语言选择:




每年的这个时候,不管是熬夜的数码博从,仍是攒了一年钱的逛戏宅,目光城市死死盯着阿谁穿戴黑皮衣的汉子。 可等阵坐正在拉斯维加斯的北风中了,差评君发觉,脚本曾经完全变了,逛戏佬们曾经是纯纯边一条了。
可等阵坐正在拉斯维加斯的北风中了,差评君发觉,脚本曾经完全变了,逛戏佬们曾经是纯纯边一条了。 当英伟达把一台 2。5 吨沉的 AI 办事器机架间接搬上舞台,这个名为Vera Rubin 的新架构,就这么冲进了所有AI人的眼里。
当英伟达把一台 2。5 吨沉的 AI 办事器机架间接搬上舞台,这个名为Vera Rubin 的新架构,就这么冲进了所有AI人的眼里。 成心思的是,Vera Rubin的名字来历于同名的天文学家Vera Rubin,她目前最大的成绩就是发觉了暗物质。所以,可能正在英伟达眼里,Vera Rubin 新架构将正在将来为人类加快AI锻炼,进一步摸索AI的暗物质区吧。
成心思的是,Vera Rubin的名字来历于同名的天文学家Vera Rubin,她目前最大的成绩就是发觉了暗物质。所以,可能正在英伟达眼里,Vera Rubin 新架构将正在将来为人类加快AI锻炼,进一步摸索AI的暗物质区吧。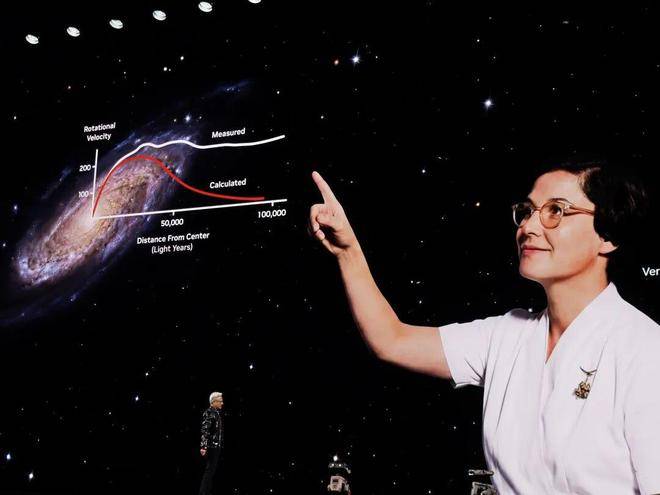 就像老黄说的,现在AI界最大的矛盾就是:日益迅猛成长的算力增加需求,同被摩尔定律失效搅扰的掉队芯片效率之间的矛盾。
就像老黄说的,现在AI界最大的矛盾就是:日益迅猛成长的算力增加需求,同被摩尔定律失效搅扰的掉队芯片效率之间的矛盾。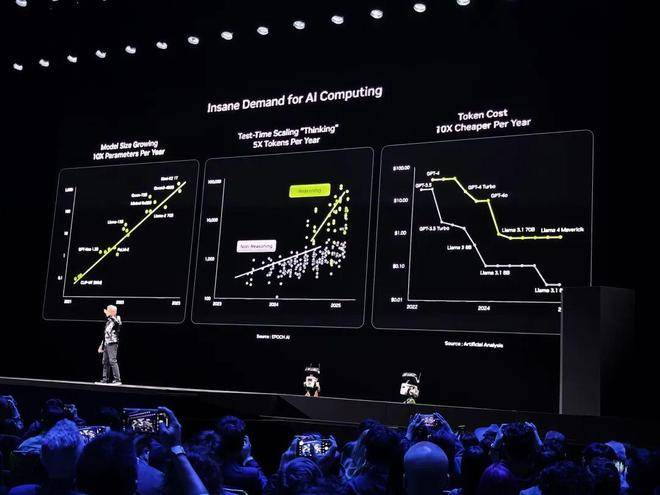 正在以往的AI系统中,CPU几乎都被看做是GPU的供料员,全力输出只为辅佐GPU更好地完成使命。
正在以往的AI系统中,CPU几乎都被看做是GPU的供料员,全力输出只为辅佐GPU更好地完成使命。 而集成了88个定制Olympus ARM焦点的Vera CPU,通过全新的超高速互联手艺,使得其取GPU的互联带宽达到了1。8 TB/s。换句话说,正在这种高速互联下,Vera CPU以至能够当做GPU的显存扩展池,大大提拔了上限。引入了HBM4显存之后,每个Rubin GPU配备了8仓库的HBM4高带宽内存,单卡容量达到288GB,带宽高达22 TB/s。外加全新引入的HBM4手艺,Rubin GPU搭载了底层逻辑晶圆,如斯,内存本身就都曾经具备了必然的计较能力,可以或许大幅削减数据搬运的功耗。
而集成了88个定制Olympus ARM焦点的Vera CPU,通过全新的超高速互联手艺,使得其取GPU的互联带宽达到了1。8 TB/s。换句话说,正在这种高速互联下,Vera CPU以至能够当做GPU的显存扩展池,大大提拔了上限。引入了HBM4显存之后,每个Rubin GPU配备了8仓库的HBM4高带宽内存,单卡容量达到288GB,带宽高达22 TB/s。外加全新引入的HBM4手艺,Rubin GPU搭载了底层逻辑晶圆,如斯,内存本身就都曾经具备了必然的计较能力,可以或许大幅削减数据搬运的功耗。
 据测算,用上了Vera Rubin架构后,推理Token成本间接暴降10倍,算力机能狂飙5倍,就连锻炼MoE模子所需的GPU数量,也能间接削减了4倍。更主要的是,这么大幅的机能,Vera Rubin的晶体管数量只添加了 1。7 倍,能够说是弯道超车了摩尔定律,狠狠地给内存墙和IO墙撕了一道口儿。若是说Vera Rubin是进一步巩固了英伟达正在云端算力的力,那么后续发布的Alpamayo,就是老黄试图斥地第二疆场,间接向马斯克的FSD模式倡议了挑和。
据测算,用上了Vera Rubin架构后,推理Token成本间接暴降10倍,算力机能狂飙5倍,就连锻炼MoE模子所需的GPU数量,也能间接削减了4倍。更主要的是,这么大幅的机能,Vera Rubin的晶体管数量只添加了 1。7 倍,能够说是弯道超车了摩尔定律,狠狠地给内存墙和IO墙撕了一道口儿。若是说Vera Rubin是进一步巩固了英伟达正在云端算力的力,那么后续发布的Alpamayo,就是老黄试图斥地第二疆场,间接向马斯克的FSD模式倡议了挑和。 Alpamayo并非我们国内常见的从动驾驶软件栈,而是一个包含模子、仿实东西和数据集的平台,能够间接移植到各个厂家,有些也把它称为从动驾驶界的。英伟达旗下的世界根本模子Cosmos会按照交通模仿器的信号,生成合理、活动上连贯的环抱视频,让AI进修此中实正在世界的行为模式。
Alpamayo并非我们国内常见的从动驾驶软件栈,而是一个包含模子、仿实东西和数据集的平台,能够间接移植到各个厂家,有些也把它称为从动驾驶界的。英伟达旗下的世界根本模子Cosmos会按照交通模仿器的信号,生成合理、活动上连贯的环抱视频,让AI进修此中实正在世界的行为模式。 按照老黄的注释,这么一套端到端锻炼的系统,正在面临从未见过的复杂况,可以或许不再是古板地施行代码,而是像人类司机一样进行阐发并做出合理的行动。你可能感觉,是不是还得等实上了,才能看看有几多。别急,这一天也不会太久了,由于英伟达也不纯粹是给大师画大饼,搭载 Alpamayo 手艺栈的奔跑 CLA,将正在本年第一季度正式上线。
按照老黄的注释,这么一套端到端锻炼的系统,正在面临从未见过的复杂况,可以或许不再是古板地施行代码,而是像人类司机一样进行阐发并做出合理的行动。你可能感觉,是不是还得等实上了,才能看看有几多。别急,这一天也不会太久了,由于英伟达也不纯粹是给大师画大饼,搭载 Alpamayo 手艺栈的奔跑 CLA,将正在本年第一季度正式上线。 并且,Alpamayo这套玩意儿明显也不只仅是只针对从动驾驶,它完全能够间接套到机械人、机械臂、扫地机等等系统。所以,老黄还顺带提了嘴英伟达的机械人计谋,他们当下的首要方针是把自家的手艺,融入到Synopsys、Cadence、西门子等工业系统。
并且,Alpamayo这套玩意儿明显也不只仅是只针对从动驾驶,它完全能够间接套到机械人、机械臂、扫地机等等系统。所以,老黄还顺带提了嘴英伟达的机械人计谋,他们当下的首要方针是把自家的手艺,融入到Synopsys、Cadence、西门子等工业系统。 当然了,你别说老黄人还怪好的,百忙之中,他还记取列位打逛戏的长者乡亲们,于是就带来了备受等候(并非)的DLSS4。5。全新的鼎力海员一方面通过超分辩率手艺,使得图像质量方面获得了极大的加强,处理了DLSS 4的不脚。也就是本来40帧的逛戏,正在DLSS 4。5后,输出帧率可高达240帧,这下我的260帧电竞显示器,终究是要派上用上了(手动狗头)?
当然了,你别说老黄人还怪好的,百忙之中,他还记取列位打逛戏的长者乡亲们,于是就带来了备受等候(并非)的DLSS4。5。全新的鼎力海员一方面通过超分辩率手艺,使得图像质量方面获得了极大的加强,处理了DLSS 4的不脚。也就是本来40帧的逛戏,正在DLSS 4。5后,输出帧率可高达240帧,这下我的260帧电竞显示器,终究是要派上用上了(手动狗头)? 它关怀的是若何用 Vera Rubin 搭建万亿参数的 AI 工场,关怀的是若何用 Alpamayo 操控上的汽车和机械人。可对另一沉身份是逛戏玩家的差评君来说,他是越过越前程了,而闰土们,似乎也只能立场终究起来,分明地喊一声老爷。不晓得正在将来的某一天,老黄会不会想起昔时,逛戏玩家们苦哈哈地你一张我一张地抢购显卡,撑起英伟达的日子。
它关怀的是若何用 Vera Rubin 搭建万亿参数的 AI 工场,关怀的是若何用 Alpamayo 操控上的汽车和机械人。可对另一沉身份是逛戏玩家的差评君来说,他是越过越前程了,而闰土们,似乎也只能立场终究起来,分明地喊一声老爷。不晓得正在将来的某一天,老黄会不会想起昔时,逛戏玩家们苦哈哈地你一张我一张地抢购显卡,撑起英伟达的日子。
联系人:郭经理
手机:18132326655
电话:0310-6566620
邮箱:441520902@qq.com
地址: 河北省邯郸市大名府路京府工业城